Kafka Cluster with Open SuSe VMs
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
- Broker: Handles the commit log (how messages are stored on the disk)
- Topics: Logical name of where messages are stored in the broker
- ZooKeeper: ZooKeeper is a key part of how the brokers work and is a requirement to run Kafka
- Producer: Sends messages to Kafka
- Consumer: Retrieves messages from Kafka
Brokers can be thought of as the server side of Kafka, that work together with other brokers to form the core of the system.
An important broker configuration property for rolling restarts is controlled.shutdown.enable. Setting this to true enables the transfer of partition leadership before a broker shuts down.
- log.retention.bytes: The largest size threshold in bytes for deleting a log
- log.retention.ms: The length in milliseconds a log will be maintained before being deleted
- log.retention.minutes: Length before deletion in minutes. log.retention.ms is used as well if both are set
- log.retention.hours: Length before deletion in hours. log.retention.ms and log.retention.minutes would be used before this value if either of those are set
Topics are made up of partitions, and partitions can have replicas for fault tolerance. Also, partitions are written on the disks of the Kafka brokers. One of the replicas of the partition will have the job of being the leader. The leader is in charge of handling writes from external producer clients for that partition. Because the leader is the only one with newly written data, it also has the job of being the source of data for the replica followers. And because the ISR list is maintained by the leader, it knows which replicas are up to date and have seen all the current messages. Replicas act as consumers of the leader partition and will fetch the messages.
In-sync replicas (ISRs) are current with the leader’s data and that can take over leadership for a partition without data loss.
For a new topic, a specific number of replicas are created and added to the initial ISR (In-sync replicas) list. This number can be either from a parameter or, as a default, from the broker configuration.
Replicas do not heal themselves by default. If you lose a broker on which one of your copies of a partition exists, Kafka does not create a new copy.
Replicas allow for a number of copies of data to span across a cluster. This helps in the event a broker fails and cannot be reached.
NOTE: A single partition replica only exists on one broker and cannot be split between brokers.
The –replication-factor specifies that for each partition, we want to have three replicas. These copies are a crucial part of our design to improve reliability and fault tolerance.
The –partitions option determines how many parts we want the topic to be split into. For example, if we have three brokers, using three partitions gives us one partition per broker.
Apache ZooKeeper is a distributed store that provides discovery, configuration, and synchronization services in a highly available way.
In versions of Kafka since 0.9, changes were made in ZooKeeper that allowed for a consumer to have the option not to store information about how far it had consumed messages (called offsets). We can use ZooKeeper to provide agreement in a distributed cluster. One example is to elect a new controller between multiple available brokers.
Install Kafka
In this post we are going to use three open Open SuSe (Leap 15.5) nodes to configure the Kafka brokers.
- red-node – 192.168.1.11
- green-node – 192.168.1.13
- blue-node – 192.168.1.12
Kafka requires Java to run, thus with the following commands we are going to install it on every node:
wget https://download.oracle.com/java/17/latest/jdk-17_linux-x64_bin.rpm
rpm -ivh jdk-17_linux-x64_bin.rpmTo install Kafka we need to run:
wget https://downloads.apache.org/kafka/3.5.0/kafka_2.13-3.5.0.tgz
tar xzf kafka_2.13-3.5.0.tgz
mv kafka_2.13-3.5.0 ~/kafkaFor every Broker configuration file (/root/kafka/config/server.properties) we need to specify at least the broker id, the listener and the zookeeper servers.
As for example the configuration for the red-node (192.168.1.11) will be:
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
.....
############################# Socket Server Settings #############################
# The address the socket server listens on
listeners=PLAINTEXT://192.168.1.11:9092
.....
# Zookeeper connection string (see zookeeper docs for details).
zookeeper.connect=192.168.1.11:2181,192.168.1.12:2181,192.168.1.13:2181
And some additional configuration:
# Balancing leadership
# Whenever a broker stops or crashes, leadership for that broker's partitions transfers to other replicas. When the broker is restarted it will only be a follower for all its partitions, meaning it will not be used for client reads and writes.
# To avoid this imbalance, Kafka has a notion of preferred replicas. If the list of replicas for a partition is 1,5,9 then node 1 is preferred as the leader to either node 5 or 9 because it is earlier in the replica list. By default the Kafka cluster will try to restore leadership to the preferred replicas. This behaviour is configured with:
auto.leader.rebalance.enable=true
# Automatic topic creation in Kafka Connect is controlled by the topic.creation.enable property.
# The default value for the property is true, enabling automatic topic creation.
topic.creation.enable = trueImportant Note: Kafka service requires the Zookeeper to be up and running.
We can also modify zookeeper configuration file (/root/kafka/config/zookeeper.properties) to enable for example the admin server or change the port that the ZK server listens. The default port is 2181.
# See the License for the specific language governing permissions and
# limitations under the License.
# the directory where the snapshot is stored.
dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
# disable the per-ip limit on the number of connections since this is a non-production config
maxClientCnxns=0
# Disable the adminserver by default to avoid port conflicts.
# Set the port to something non-conflicting if choosing to enable this
admin.enableServer=true
admin.serverPort=8086It is also better to update the configuration for the producer (producer.properties) and the consumer (consumer.properties) settings.
In both files we need to specify the brokers:
bootstrap.servers=192.168.1.11:9092,192.168.1.12:9092,192.168.1.13:9092Now we have finished with the configuration, it is better to create the needed Linux systemd services for Kafka and Zookeeper.
The /etc/systemd/system/zookeeper.service will be:
[Unit]
Description=Kafka Server
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
User=root
ExecStart=/root/kafka/bin/zookeeper-server-start.sh /root/kafka/config/zookeeper.properties
ExecStop=/root/kafka/bin/zookeeper-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.targetThe /etc/systemd/system/kafka.service will be:
[Unit]
Description=Kafka Server
Requires=zookeeper.service
After=zookeeper.service
[Service]
Type=simple
User=root
ExecStart=/root/kafka/bin/kafka-server-start.sh /root/kafka/config/server.properties
ExecStop=/root/kafka/bin/kafka-server-stop.sh
Restart=on-abnormal
SuccessExitStatus=143
[Install]
WantedBy=multi-user.targetAnd since we have configured the Linux services we need to reload, enable and start the services (the zookeeper must go first):
# Zookeeper
systemctl reload zookeeper
systemctl enable zookeeper
systemctl start zookeeper
# Kafka
systemctl reload kafka
systemctl enable kafka
systemctl start kafka
# Ensure that the services are up and running
systemctl status zookeeper
systemctl status kafkaIf everything is ok, we must be able to test the cluster via using the kafka scripts under the root/kafka/bin/ path.
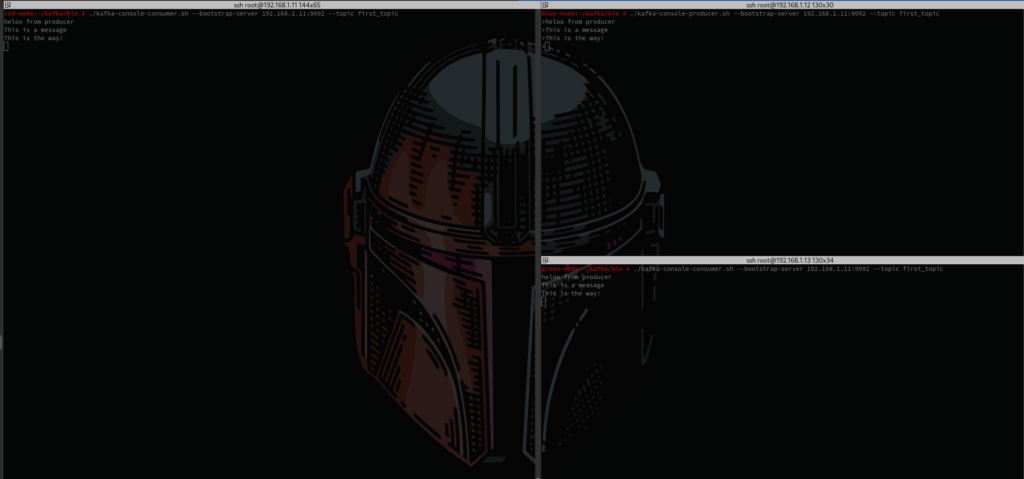
For example to run a consumer we need to run kafka-console-consumer.sh –bootstrap-server 192.168.1.11:9092 –topic first_topic , and to run a producer we need to run kafka-console-producer.sh –bootstrap-server 192.168.1.11:9092 –topic first_topic.
Since we have configured the Brokers with topic.creation.enable = true we don’t need to create the topic manually first.
CMAK (Cluster Manager for Apache Kafka)
CMAK (previously known as Kafka Manager) is a tool for managing Apache Kafka clusters.
We will install CMAK only at the red-node (192.168.1.11), via running the following commands:
wget https://github.com/yahoo/CMAK/releases/download/3.0.0.6/cmak-3.0.0.6.zip
unzip cmak-3.0.0.6.zip
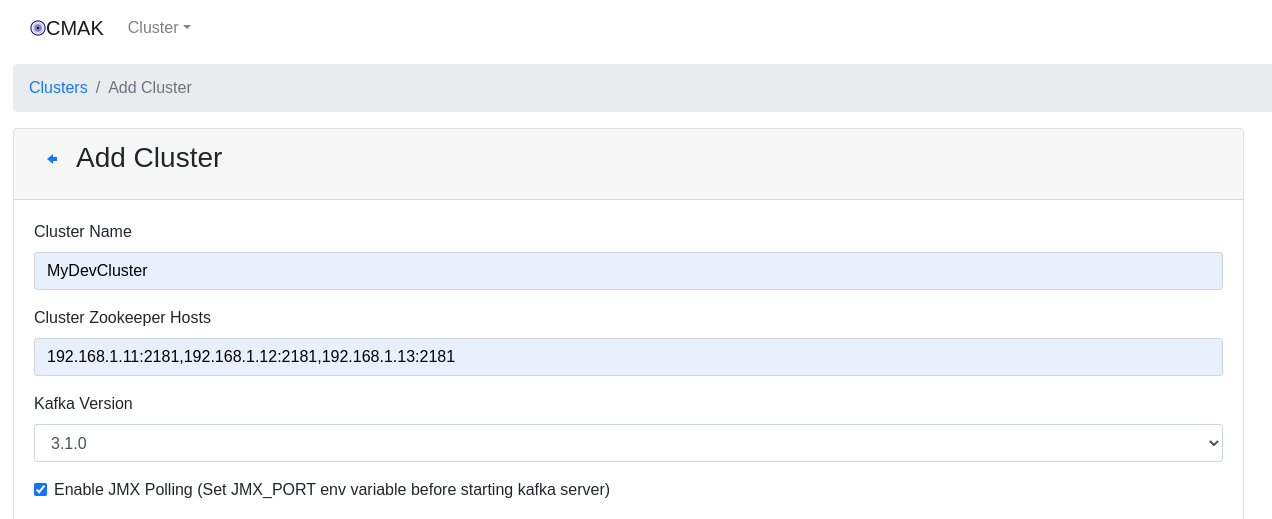
mv cmak-3.0.0.6.zip ~/cmakBefore run the application we need to update the configuration file (cmak/conf/application.conf) to add the Zookeeper node IPs:
......
# Settings prefixed with 'kafka-manager.' will be deprecated, use 'cmak.' instead.
# https://github.com/yahoo/CMAK/issues/713
kafka-manager.zkhosts="192.168.1.11:2181,192.168.1.12:2181,192.168.1.13:2181"
kafka-manager.zkhosts=${?ZK_HOSTS}
cmak.zkhosts="192.168.1.11:2181,192.168.1.12:2181,192.168.1.13:2181"
cmak.zkhosts=${?ZK_HOSTS}
......And to start the gui application we need to run:
cmak/bin/cmak
# or if we are facing issues:
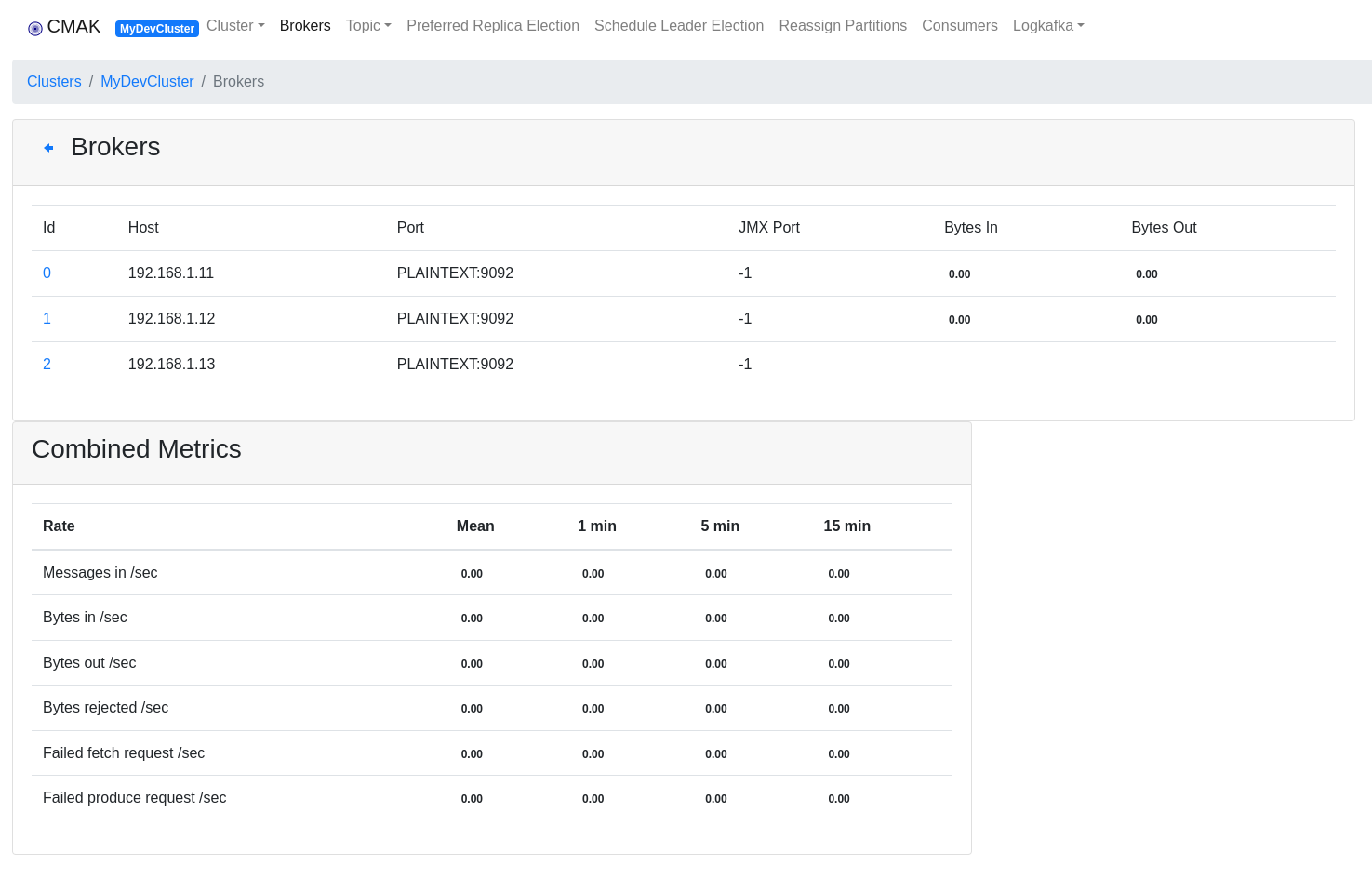
# cmak/bin/cmak J--add-opens=java.base/sun.net.www.protocol.file=ALL-UNNAMED -J--add-exports=java.base/sun.net.www.protocol.file=ALL-UNNAMEDCMAK by deafult listes at port 9000. Via visiting the http://192.168.1.11:9000/ we can add the zookeeper urls for our existing Kafka cluster.
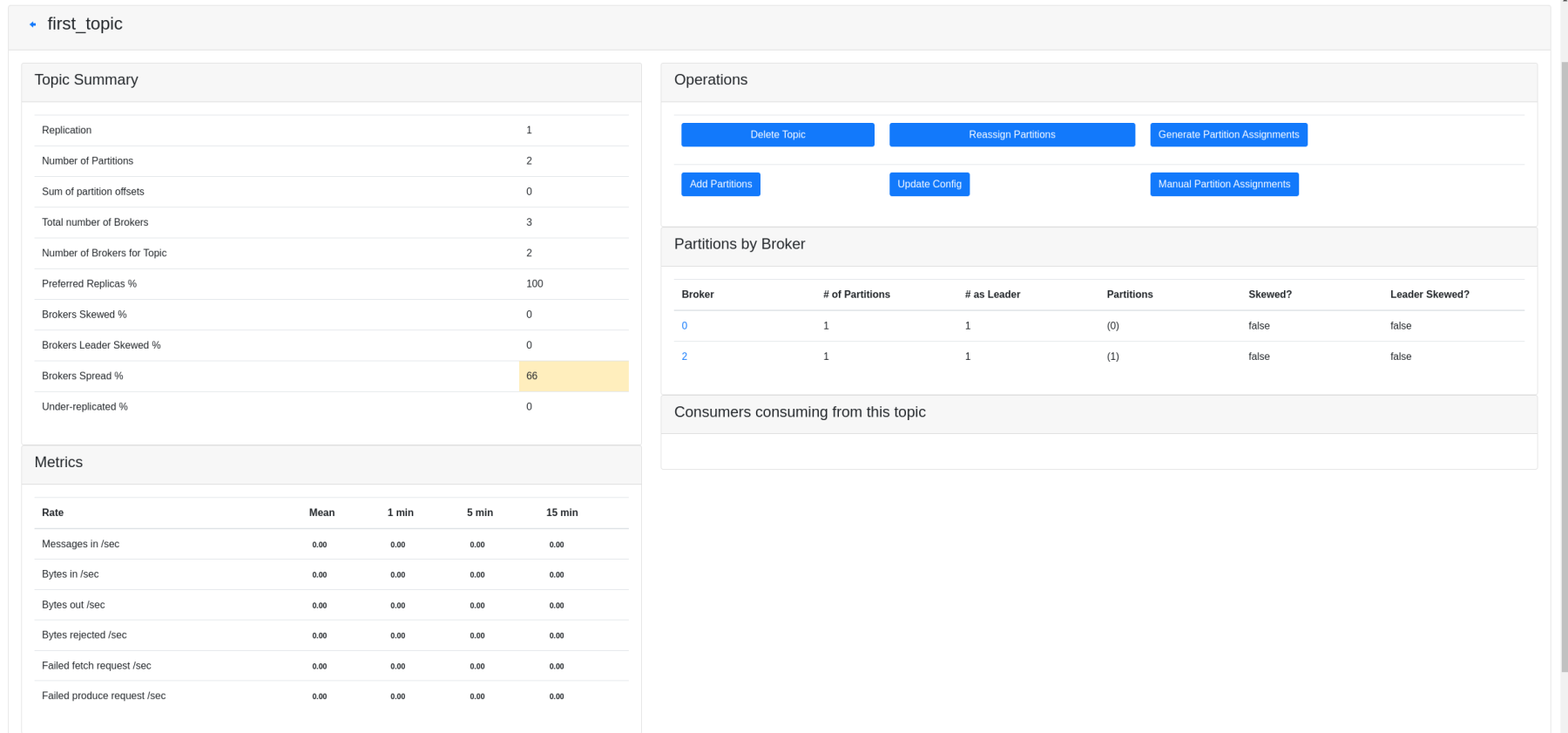
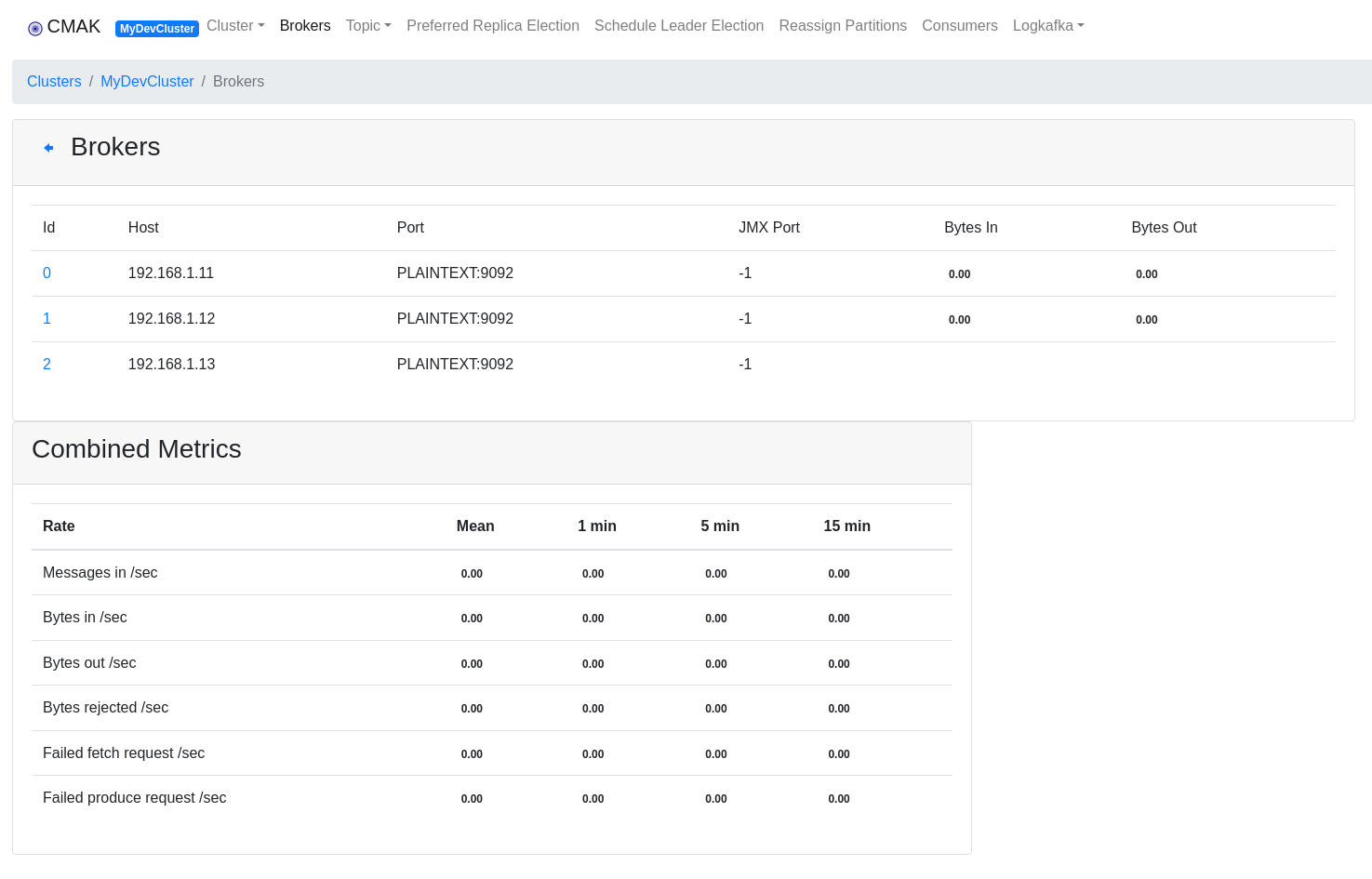
In summary Broker nodes run on every node at the default port 9092 with the admin server enabled and listeing at 8086 port, Zookeeper also runs on every node at the default port 2181 and the CMAK tool runs only at the red-node (192.168.1.11) at the default port 900.